Problème FPU périodique : implémentation CUDA
1. Introduction
Dans le problème de Fermi-Pasta-Ulam (FPU), une chaînes d'oscillateurs couplés comporte des termes non-linéaires. L'équation du mouvement d'une masse de la chaîne est :
On considère ici le cas de conditions limites périodiques, où la dernière masse de la chaîne est reliée à la première (chaîne en boucle). Contrairement au système à bords fixes étudiés en [1], les conditions limites périodiques permettent d'obtenir des ondes progressives.
Lorsque la chaîne est linéaire (b=0), les équations du mouvement sont intégrables. La solution est étudiée dans Chaînes d'oscillateurs linéaires en boucle.
2. Méthode de calcul
Les équations du mouvement (1) sont intégrés numériquement avec une méthode symplectique, la méthode de Stormer-Verlet. Les méthodes symplectiques s'appliquent aux systèmes conservatifs et permettent d'obtenir une énergie à peu près constante sur les temps longs.
Initialement, la chaîne est placée dans un mode propre du problème linéaire. Les modes propres sont des ondes progressives sinusoïdales. Le mode propre d'indice m est défini par :
La vitesse de propagation de ce mode (toujours dans le cas b=0) est :
Pour les modes de faible longueur d'onde (m proche de N/2), le système est dispersif. Pour les grandes longueurs d'onde (m petit devant N) la vitesse est vm=ω0 et le système est non dispersif.
L'analyse du mouvement comporte un calcul des coordonnées normales selon la transformation :
Sous forme matriciel, la transformation s'écrit :
Ce calcul nécessite N2 opérations. Avec l'algorithme FFT, le nombre d'opération est en N ln(N). Nous avons néanmoins opté pour un produit matriciel complet, très rapide sur l'architecture parallèle CUDA. Par ailleurs, il n'est pas toujours nécessaire de calculer les modes de haute fréquence.
Théoriquement, les coordonnées ξm et ξN-m correspondent à deux ondes sinusoïdales se propageant en sens inverse. Cependant, cette différentiation n'est possible que si les déplacements qk sont sous forme complexe. Dans la simulation, les déplacements sont réels et on a :
On peut donc se contenter de calculer (au plus) la moitié des coordonnées normales.
L'énergie de chaque mode est calculée par :
Pour suivre l'évolution de la forme de l'onde au cours de sa progression (elle traverse la chaîne des milliers de fois), on se place dans le repère qui se déplace à la vitesse vm définie par (5). Dans ce repère, l'onde sinusoïdale est stationnaire (si b=0). Dans le cas d'une faible non-linéarité, l'onde n'est plus stationnaire dans ce repère mais son déplacement reste très lent.
3. Programme Python-CUDA
Le programme ci-dessous fpuPerCuda.py tourne avec une carte graphique NVidia compatible CUDA. Il nécessite les modules Python PyCUDA et Numpy.
Chaque masse de la chaîne est traitée par un thread. Tous les threads appartiennent au même bloc. Le nombre N maximal de masses dans la chaîne est donc égal au nombre maximal de threads par bloc (512 ou 1024 sur les cartes les plus récentes).
Le module comporte une classe FpuPerCuda. Le nombre de variables nvar (c'est-à-dire le nombre N d'oscillateurs de la chaîne), est fourni au constructeur. Celui-ci définit les différentes fonctions (langage C) qui seront exécutées sur le GPU.
La première fonction définit la dérivée de l'énergie potentielle par rapport aux positions. Chaque thread traite une variable, repérée par l'indice k.
import pycuda.autoinit
import pycuda.driver as cuda
from pycuda.compiler import SourceModule
import numpy
import math
import time
class FpuPerCuda:
def __init__(self,nvar):
self.nvar = nvar
f1 = """__device__ void dPotential(int k, int nvar, float b, float n, float *q, float *dp) {
float x1,x2;
if (k==0) {x1=q[0]-q[nvar-1]; x2=q[1]-q[0];}
else if (k==nvar-1) {x1 = q[k]-q[k-1]; x2=-q[k]+q[0];}
else {x1=q[k]-q[k-1]; x2=-q[k]+q[k+1];}
dp[k] = x1-x2+b*(powf(x1,n)-powf(x2,n));
}"""
La seconde fonction effectue un pas élémentaire de la méthode de Stormer-Verlet. Le pas de temps est h.
f2 = """__device__ void verletStep(int k, float h, int nvar, float b, float n, float *q, float *p, float *dp) {
dPotential(k,nvar,b,n,q,dp);
p[k] -= 0.5*h*dp[k];
q[k] += h*p[k];
__syncthreads();
dPotential(k,nvar,b,n,q,dp);
p[k] -= 0.5*h*dp[k];
__syncthreads();
}"""
La fonction suivante calcule l'énergie de la chaîne. Chaque thread calcule l'énergie d'une masse puis le calcul de la somme est partagé entre les threads.
f3 = """__device__ void energy(int nvar,float b, float n, float *q, float *p, float *e) {
float x1;
int k = threadIdx.x;
if (k==0) x1=q[k]-q[nvar-1];
else x1=q[k]-q[k-1];
e[k] = 0.5*p[k]*p[k]+0.5*(x1*x1)+1.0/(n+1)*b*powf(x1,n+1);
__syncthreads();
int i = blockDim.x/2;
while (i!=0) {
if (k < i) e[k] += e[k+i];
__syncthreads();
i /= 2;
}
}"""
La fonction suivante est appelée depuis le CPU (mot clé __global__). Elle effectue plusieurs pas de la méthode de Stormer-verlet (nsteps). L'état initial est fourni dans les tableaux q0 et p0, lesquels servent aussi à récupérer l'état final. Le tableau en (un seul élément) contient à la fin l'énergie du système. Les tableaux utilisés pour les calculs sont dans la mémoire locale du processeur (mot clé __shared__).
f4="""__global__ void verletMultiSteps(int nsteps, float h, int nvar, float b, float n, float *q0, float *p0, float *en) {
__shared__ float q[%d];
__shared__ float p[%d];
__shared__ float dp[%d];
__shared__ float e[%d];
int i;
int k = threadIdx.x;
q[k] = q0[k];
p[k] = p0[k];
__syncthreads();
for (i=0; i<nsteps; i++) verletStep(k,h,nvar,b,n,q,p,dp);
q0[k] = q[k];
p0[k] = p[k];
energy(nvar,b,n,q,p,e);
if (k==0) en[0] = e[0];
}"""%(nvar,nvar,nvar,nvar)
La fonction suivante calcule l'énergie des modes propres. Les tableaux reA et imA contiennent la partie réelle et la partie imaginaire de la matrice A des vecteurs propres (matrice de passage des déplacements aux coordonnées normales). Le tableau omeg2 contient les valeurs propres (carré des pulsations propres). Les énergies des modes sont retournées dans le tableau emode.
f5="""__global__ void modeEnergy(float *q, float *p, float *reA, float *imA, float *omeg2, float *emode) {
__shared__ float rexi[%d];
__shared__ float imxi[%d];
__shared__ float redxi[%d];
__shared__ float imdxi[%d];
int i = blockIdx.x; // mode
int j = threadIdx.x; // variable
int index = j+blockDim.x*i;
rexi[j] = reA[index]*q[j];
imxi[j] = imA[index]*q[j];
redxi[j] = reA[index]*p[j];
imdxi[j] = imA[index]*p[j];
__syncthreads();
int j1 = blockDim.x/2;
while (j1!=0) {
if (j < j1) {
rexi[j] += rexi[j+j1];
imxi[j] += imxi[j+j1];
redxi[j] += redxi[j+j1];
imdxi[j] += imdxi[j+j1];
}
__syncthreads();
j1 /= 2;
}
if (j==0) emode[i] = 0.5*(redxi[0]*redxi[0]+imdxi[0]*imdxi[0]+omeg2[i]*(rexi[0]*rexi[0]+imxi[0]*imxi[0]));
}"""%(nvar,nvar,nvar,nvar)
Compilation du code CUDA :
mod=SourceModule(f1+"\n"+f2+"\n"+f3+"\n"+f4+"\n"+f5)
self.verletMultiSteps = mod.get_function("verletMultiSteps")
self.modeEnergy = mod.get_function("modeEnergy")
Calcul de la matrice de changement de coordonnées (matrice des vecteurs propres) et du tableau des valeurs propres :
self.reA=numpy.empty(shape=(self.nvar,self.nvar),dtype=numpy.float32)
self.imA=numpy.empty(shape=(self.nvar,self.nvar),dtype=numpy.float32)
s=math.sqrt(1.0/self.nvar)
r=math.pi*2/self.nvar
for i in range(self.nvar):
for j in range(self.nvar):
self.reA[i,j]=s*math.cos(r*(i+1)*(j+1))
self.imA[i,j]=-s*math.sin(r*(i+1)*(j+1))
self.omeg2=numpy.empty(shape=self.nvar,dtype=numpy.float32)
r=math.pi/self.nvar
for i in range(self.nvar):
self.omeg2[i] = 4*math.pow(math.sin((i+1)*r),2)
Création des tableaux des déplacements et des vitesses :
self.q0 = numpy.empty(shape=self.nvar,dtype=numpy.float32)
self.p0 = numpy.empty(shape=self.nvar,dtype=numpy.float32)
La fonction init initialise la chaîne dans un mode, dont l'indice est précisé en argument. La vitesse de propagation du mode est aussi calculée.
def init(self,m):
wm=2*math.sin(math.pi*m/self.nvar)
for k in range(self.nvar):
self.q0[k] = math.cos(2*math.pi*(k+1)*m/self.nvar)
self.p0[k] = wm*math.sin(2*math.pi*(k+1)*m/self.nvar)
self.vm = self.nvar/(math.pi*m)*math.sin(math.pi*m/self.nvar)
La fonction run effectue un calcul complet. h est le pas de temps, n1 est la taille d'un bloc de calcul, c'est-à-dire le nombre de pas élémentaires entre deux calculs des coordonnées normales, n2 le nombre de blocs de calcul. b et n sont les paramètres du terme non linéaire, définis dans l'équation (1). L'argument nm est le nombre de modes à calculer.
def run(self,h,n1,n2,b,n,nm):
if nm>self.nvar:
nm = self.nvar
self.t = numpy.arange(n2)*h*n1
self.qmat=numpy.empty(shape=(n2,self.nvar),dtype=numpy.float32)
self.pmat=numpy.empty(shape=(n2,self.nvar),dtype=numpy.float32)
en=numpy.empty(shape=(1),dtype=numpy.float32)
self.emat=numpy.empty(shape=(n2,1),dtype=numpy.float32)
self.emodemat=numpy.empty(shape=(n2,self.nvar),dtype=numpy.float32)
self.qstat=numpy.empty(shape=(n2,self.nvar),dtype=numpy.float32)
self.pstat=numpy.empty(shape=(n2,self.nvar),dtype=numpy.float32)
#memoire GPU
dev_q0 = cuda.mem_alloc(self.q0.nbytes)
dev_p0 = cuda.mem_alloc(self.p0.nbytes)
dev_en = cuda.mem_alloc(en.nbytes)
dev_reA = cuda.mem_alloc(self.reA.nbytes)
dev_imA = cuda.mem_alloc(self.imA.nbytes)
dev_omeg2 = cuda.mem_alloc(self.omeg2.nbytes)
dev_emode = cuda.mem_alloc(self.q0.nbytes)
cuda.memcpy_htod(dev_q0,self.q0)
cuda.memcpy_htod(dev_p0,self.p0)
cuda.memcpy_htod(dev_reA,self.reA)
cuda.memcpy_htod(dev_imA,self.imA)
cuda.memcpy_htod(dev_omeg2,self.omeg2)
ta = time.time()
# boucle de calcul
for i2 in range(n2):
self.verletMultiSteps(numpy.uint32(n1),numpy.float32(h),numpy.uint32(self.nvar),numpy.float32(b),numpy.float32(n),dev_q0,dev_p0,dev_en,grid=(1,1),block=(self.nvar,1,1))
self.modeEnergy(dev_q0,dev_p0,dev_reA,dev_imA,dev_omeg2,dev_emode,grid=(nm,1),block=(self.nvar,1,1))
cuda.memcpy_dtoh(self.qmat[i2],dev_q0)
cuda.memcpy_dtoh(self.pmat[i2],dev_p0)
cuda.memcpy_dtoh(self.emat[i2],dev_en)
cuda.memcpy_dtoh(self.emodemat[i2],dev_emode)
dec = numpy.int(self.vm*h*n1*(i2+1)) #position du repere mobile
self.qstat[i2] = numpy.roll(self.qmat[i2],-dec) # deplacements dans le repere mobile
self.pstat[i2] = numpy.roll(self.pmat[i2],-dec)
print "%d sur %d"%(i2,n2)
cuda.memcpy_dtoh(self.q0,dev_q0)
cuda.memcpy_dtoh(self.p0,dev_p0)
print "Duree du calcul (s) : %f"%(time.time()-ta)
self.deltaE = numpy.std(self.emat)/numpy.average(self.emat)
print "Ecart type relatif de E : %e"%self.deltaE
Les valeurs mémorisées à la fin de chaque bloc de calcul sont disponibles dans les tableaux suivants :
- t : instants
- qmat : déplacements des points de la chaîne.
- pmat : vitesses des points de la chaîne.
- qstat : déplacements des points de la chaîne dans le repère mobile de vitesse vm.
- pstat : vitesses des points de la chaîne, leurs positions étant rapportées au repère mobile.
- emat : énergie totale de la chaîne.
- emodemat : énergies des modes propres.
- deltaE : écart type relatif de l'énergie totale.
4. Exemple
La chaîne a 256 masses. Une faible non-linéarité quadratique est définie. La chaîne est placée initialement dans le mode 1.
import fpuPerCuda
from pylab import *
import numpy
fpu=fpuPerCuda.FpuPerCuda(256)
fpu.init(1)
h=0.1
n1=8000
n2=500
b=0.1
n=2
nm=10
fpu.run(h,n1,n2,b,n,nm)
On trace l'énergie des 10 premiers modes en fonction du temps (divisé par n1h) :
figure(0)
for m in range(nm):
plot(fpu.emodemat[:,m])
axis([0,n2*1.5,0,0.05])
legend(("mode 1","mode 2","mode 3","mode4","mode 5","mode 6","mode 7","mode 8","mode 9","mode 10"),loc='upper right')
xlabel("t/(n1h)")
ylabel("Em")
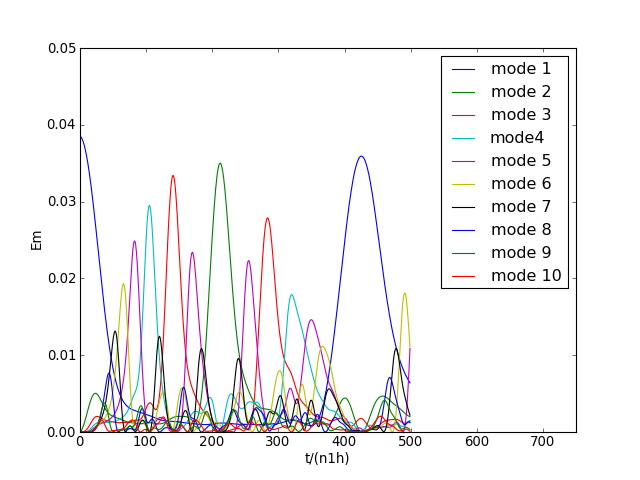 plotA.pdf
plotA.pdf
Les déplacements dans le répère mobile sont représentés sous forme d'une image :
matshow(numpy.transpose(fpu.qstat))
xlabel("t/(n1h)")
ylabel("k")
title("q")
colorbar()
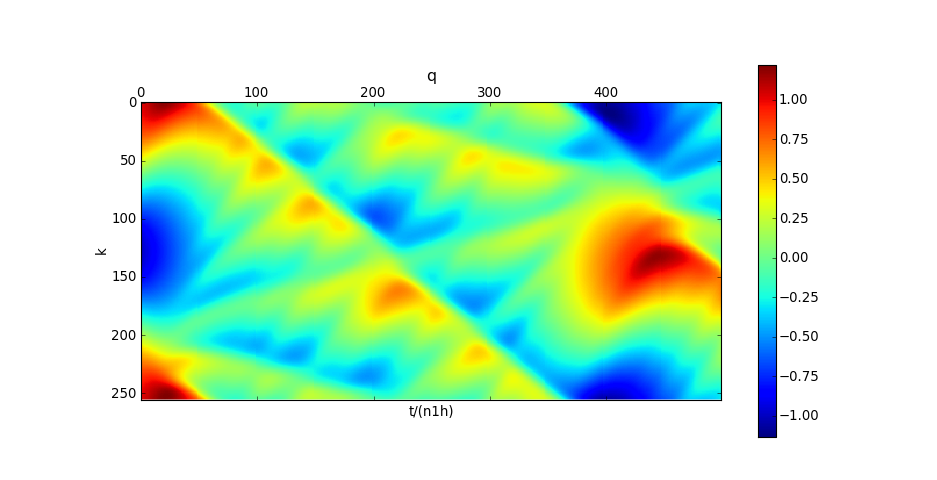 plotB.pdf
plotB.pdf
De même pour les vitesses :
matshow(numpy.transpose(fpu.pstat))
xlabel("t/(n1h)")
ylabel("k")
title("p")
colorbar()
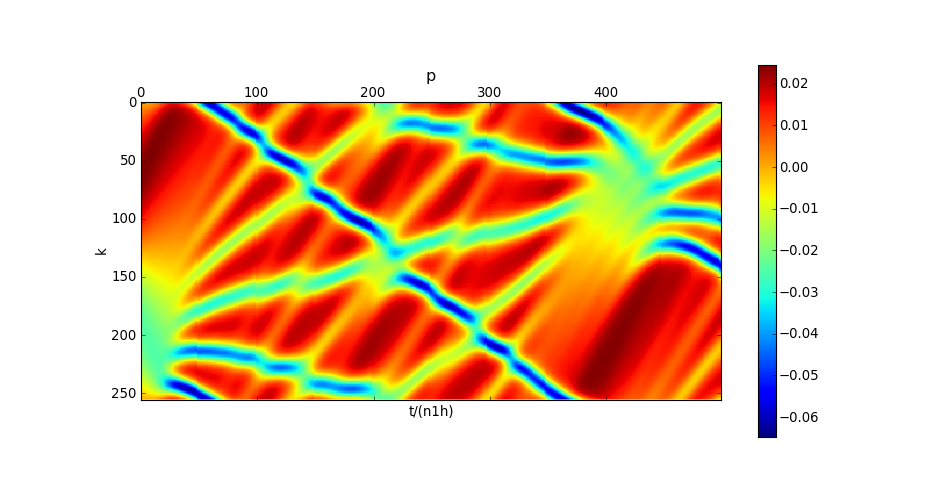 plotC.pdf
plotC.pdf
On observe sur ces figures le retour du mode fondamental vers t=450n1h. Voyons plus précisément la forme de l'onde dans le repère mobile à t=100n1h :
figure(3)
plot(fpu.qstat[100,:])
xlabel("k")
ylabel("qk")
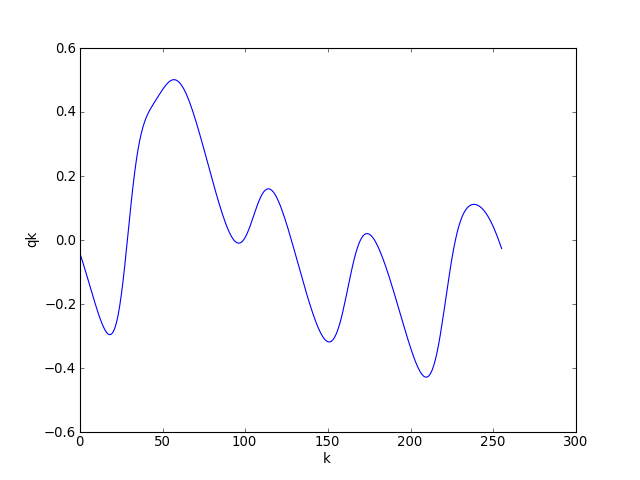 plotD.pdf
plotD.pdf
figure(4)
plot(fpu.pstat[100,:])
xlabel("k")
ylabel("pk")
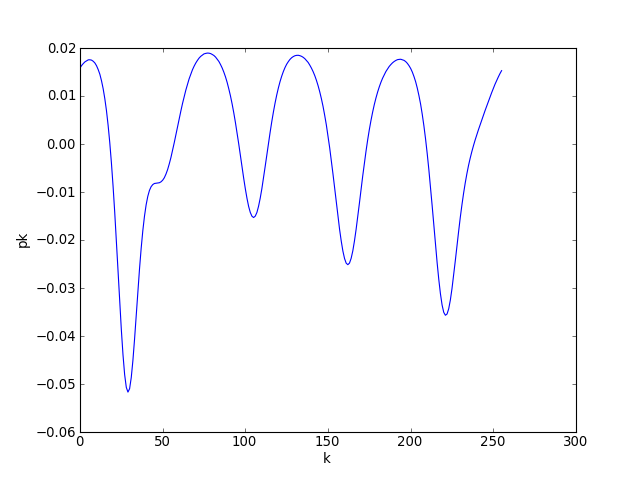 plotE.pdf
plotE.pdf